
Learning Microsoft Fabric Analytics Engineer certification DP-600 exam requires complete guide, latest DP-600 exam resources and DP-600 exam dumps practice questions! You can go to download Pass4itSure DP-600 exam dumps practice questions https://www.pass4itsure.com/dp-600.html (pdf+vce) to practice effectively and improve your exam ability.
My purpose of writing this blog is to bring all DP-600 study resources in one place to guide you to prepare for the exam properly. I hope everyone preparing for this exam will find this blog useful and ultimately help you master all the skills you need to become a Certified Fabric Analysis Engineer.
History of Fabric
If any of you still don’t know what Fabric is and what changes it will bring to us, read on.
Fabric underlying is OneLake, what is OneLake exactly? Different tools are using the same foundation, and it enables cross-cloud, three major roles to be unified, and it’s available today.
Fabric Analysis Engineer Certification
Microsoft has launched the DP-600 exam, which will help you get certified as a Microsoft Certified Fabric Analytics Engineer.Fabric Analytics Engineer transforms data into reusable analytic assets, including semantic models, reports, data streams, data pipelines, notebooks, lakehouses, and data warehouses.
Fabric builds on the familiar Power BI experience, making the transition to analytics engineering easier and faster. This certification is perfect for Power BI data analysts who want to upgrade their skills for data engineering tasks. To learn how to become certified to take the exam, read the official Microsoft Learning page for the exam at https://learn.microsoft.com/en-us/training/courses/dp-600t00.
Late 2023 Microsoft officially releases updates to Fabric and the entire data platform at the Ignite conference.AI has arrived and the ultimate tool for the age of data analytics is being readied.
In 2024 Microsoft officially launched the DP-600 exam, which is now officially available.
For more details about the Microsoft DP-600 exam see: https://learn.microsoft.com/zh-cn/credentials/certifications/resources/study-guides/dp-600#about-the-exam
How to prepare for exam DP-600: Microsoft Fabric Analytics Engineer
Okay, got it, what is the exam? Next it’s time to talk about how to prepare for the DP-600 exam.
Let’s start with a list of ways to prepare for the exam there:
- Fabric Career Center
- Join the Fabric group for shared learning
- Practice with DP-600 exam dumps (available in PDF or VCE mode)
- Watching expert videos
- Using Microsoft Learning to understand the main content
- etc.
Focus on the Fabric Career Center and using DP-600 exam dumps.
Fabric Vocational Center
The Fabric Career Center is our one-stop platform for learning about Fabric professional growth! Officials have created a comprehensive learning journey that offers free training, as well as certification exams (for a fee). Include these:
Cloud Skills Challenge: Complete a collection of Fabric Learning Modules to receive exam discounts and prepare for the DP-600 exam.
Learning Together: Join a live session led by an expert MVP to guide through the learning modules.
Group Learning: Join Hack Together to build innovative AI solutions with Fabric and compete as a team to win exciting prizes. Participate in expert-led learning rooms and dive deeper with your group.
Career Insights: Get inspired and mentored by watching videos from the most successful experts in the Fabric community to kick off your learning journey.
Role Guidance: Learn how modern data roles fit into Fabric and the potential opportunities they can unlock for us.
Fabric Career Center at https://community.fabric.microsoft.com
Using the latest DP-600 exam dumps
When it comes to using the latest DP-600 exam dumps, it involves the question of how to choose. You must choose the latest and reliable real DP-600 exam dumps practice questions to prepare for the exam effectively. The credibility of the dumps is also important, and it is always right to choose a reputable one. You can try Pass4itSure DP-600 exam dumps practice questions. It always keeps real-time updating and follows the official exam content. Pass4itSure years of experience in providing exam questions, those who take the exam know it.
Summary of the latest DP-600 study resources (in link form)
For your easier learning, it’s all organized in link form, below:
https://learn.microsoft.com/en-us/training/browse/?products=fabric
https://learn.microsoft.com/en-us/credentials/certifications/fabric-analytics-engineer-associate/?practice-assessment-type=certification
https://learn.microsoft.com/en-us/training/browse/?roles=data-engineer
https://learn.microsoft.com/en-us/training/browse/?roles=data-analyst
https://learn.microsoft.com/en-us/training/paths/get-started-fabric/
https://learn.microsoft.com/en-us/training/paths/implement-lakehouse-microsoft-fabric/
https://learn.microsoft.com/en-us/training/paths/ingest-data-with-microsoft-fabric/
https://learn.microsoft.com/en-us/training/paths/work-with-data-warehouses-using-microsoft-fabric/
https://learn.microsoft.com/en-us/training/paths/work-semantic-models-microsoft-fabric/
https://learn.microsoft.com/en-au/credentials/certifications/resources/study-guides/dp-600
https://learn.microsoft.com/en-au/training/modules/examine-components-of-modern-data-warehouse/?source=recommendations
https://learn.microsoft.com/en-au/shows/learn-live/fabric-dp-600-cram-sessions/?source=recommendations
https://learn.microsoft.com/en-au/shows/learn-live/exam-cram-for-dp-600-ep401-how-to-pass-exam-dp-600-implementing-analytics-solutions-using-microsoft-fabric-cet?source=recommendations
https://techcommunity.microsoft.com/t5/analytics-on-azure/bd-p/AnalyticsonAzureDiscussion
https://www.microsoft.com/en-us/microsoft-fabric/blog/
Rest assured that each is a valid and useful resource for your exam.
Latest DP-600 exam questions practice questions
Not only is it up-to-date, but it is also free DP-600 Exam Practice Questions from Pass4itSure Free DP-600 Exam Dumps.
Exam Questions: 1-15
Related: DP-500
Certification: Microsoft
Question 1:
You have a Fabric tenant that contains a lakehouse named Lakehouse1. Lakehouse1 contains a subfolder named Subfolder1 that contains CSV files. You need to convert the CSV files into the delta format that has V-Order optimization enabled. What should you do from Lakehouse explorer?
A. Use the Load to Tables feature.
B. Create a new shortcut in the Files section.
C. Create a new shortcut in the Tables section.
D. Use the Optimize feature.
Correct Answer: D
Explanation: To convert CSV files into the delta format with Z-Order optimization enabled, you should use the Optimize feature (D) from Lakehouse Explorer. This will allow you to optimize the file organization for the most efficient querying.
References = The process for converting and optimizing file formats within a lakehouse is discussed in the lakehouse management documentation.
Question 2:
You to need assign permissions for the data store in the AnalyticsPOC workspace. The solution must meet the security requirements.
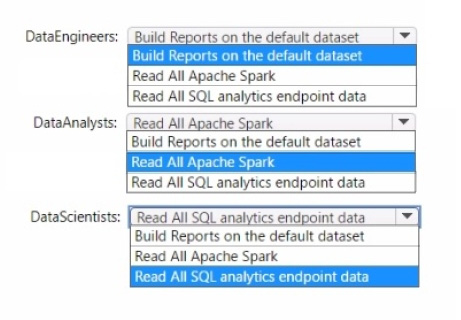
Which additional permissions should you assign when you share the data store? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
Correct Answer:
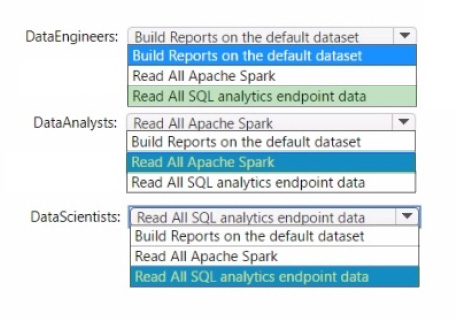
Data Engineers: Read All SQL analytics endpoint data
Data Analysts: Read All Apache Spark
Data Scientists: Read All SQL analytics endpoint data
The permissions for the data store in the AnalyticsPOC workspace should align with the principle of least privilege:
Data Engineers need read and write access but not to datasets or reports.
Data Analysts require read access specifically to the dimensional model objects and the ability to create Power BI reports.
Data Scientists need read access via Spark notebooks. These settings ensure each role has the necessary permissions to fulfill their responsibilities without exceeding their required access level.
Question 3:
You have a Fabric tenant that contains a warehouse.
A user discovers that a report that usually takes two minutes to render has been running for 45 minutes and has still not rendered.
You need to identify what is preventing the report query from completing.
Which dynamic management view (DMV) should you use?
A. sys.dm-exec_requests
B. sys.dn_.exec._sessions
C. sys.dm._exec._connections
D. sys.dm_pdw_exec_requests
Correct Answer: D
Explanation: The correct DMV to identify what is preventing the report query from completing is sys.dm_pdw_exec_requests (D). This DMV is specific to Microsoft Analytics Platform System (previously known as SQL Data Warehouse), which is the environment assumed to be used here.
It provides information about all queries and load commands currently running or that have recently run. References = You can find more about DMVs in the Microsoft documentation for Analytics Platform System.
Question 4:
You have a Microsoft Power B1 report and a semantic model that uses Direct Lake mode. From Power Si Desktop, you open Performance analyzer as shown in the following exhibit.
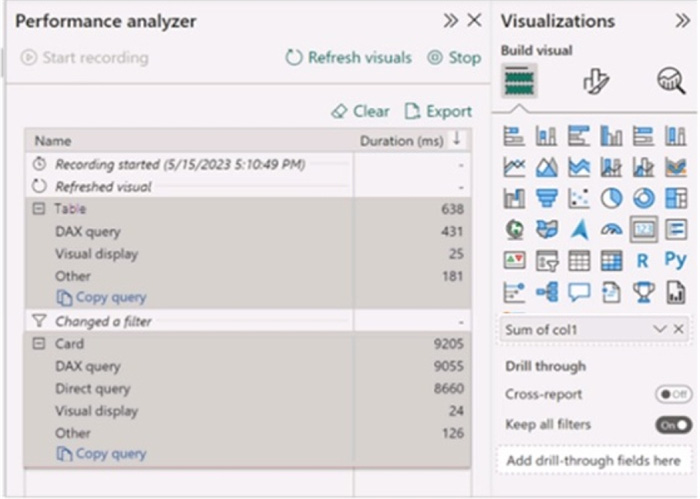
Use the drop-down menus to select the answer choice that completes each statement based on the information presented in the graphic. NOTE: Each correct selection is worth one point.
Hot Area:

Correct Answer:

The Direct Lake fallback behavior is set to: DirectQueryOnly The query for the table visual is executed by using: DirectQuery
In the context of Microsoft Power BI, when using DirectQuery in Direct Lake mode, there is no caching of data and all queries are sent directly to the underlying data source. The Performance Analyzer tool shows the time taken for different operations, and from the options provided, it indicates that DirectQuery mode is being used for the visuals, which is consistent with the Direct Lake setting.
DirectQueryOnly as the fallback behavior ensures that only DirectQuery will be used without reverting to import mode.
Question 5:
Which type of data store should you recommend in the AnalyticsPOC workspace?
A. a data lake
B. a warehouse
C. a lakehouse
D. an external Hive metaStore
Correct Answer: C
Explanation: A lakehouse (C) should be recommended for the AnalyticsPOC workspace. It combines the capabilities of a data warehouse with the flexibility of a data lake. A lakehouse supports semi-structured and unstructured data and allows for T-SQL and Python read access, fulfilling the technical requirements outlined for Litware.
References = For further understanding, Microsoft\’s documentation on the lakehouse architecture provides insights into how it supports various data types and analytical operations.
Question 6:
You have a Fabric tenant named Tenant1 that contains a workspace named WS1. WS1 uses a capacity named C1 and contains a dawset named DS1. You need to ensure read- write access to DS1 is available by using the XMLA endpoint. What should be modified first?
A. the DS1 settings
B. the WS1 settings
C. the C1 settings
D. the Tenant1 settings
Correct Answer: C
Explanation: To ensure read-write access to DS1 is available by using the XMLA endpoint, the C1 settings (which refer to the capacity settings) should be modified first. XMLA endpoint configuration is a capacity feature, not specific to individual datasets or workspaces.
References = The configuration of XMLA endpoints in Power BI capacities is detailed in the Power BI documentation on dataset management.
Question 7:
You have source data in a folder on a local computer.
You need to create a solution that will use Fabric to populate a data store. The solution must meet the following requirements:
Support the use of dataflows to load and append data to the data store.
Ensure that Delta tables are V-Order optimized and compacted automatically.
Which type of data store should you use?
A. a lakehouse
B. an Azure SQL database
C. a warehouse
D. a KQL database
Correct Answer: A
Explanation: A lakehouse (A) is the type of data store you should use. It supports dataflows to load and append data and ensures that Delta tables are Z-Order optimized and compacted automatically.
References = The capabilities of a lakehouse and its support for Delta tables are described in the lakehouse and Delta table documentation.
Question 8:
You have a Fabric tenant that contains a lakehouse.
You are using a Fabric notebook to save a large DataFrame by using the following code.

For each of the following statements, select Yes if the statement is true. Otherwise, select No. NOTE: Each correct selection is worth one point.
Hot Area:

Correct Answer:

The results will form a hierarchy of folders for each partition key. – Yes The resulting file partitions can be read in parallel across multiple nodes. – Yes The resulting file partitions will use file compression. – No
Partitioning data by columns such as year, month, and day, as shown in the DataFrame write operation, organizes the output into a directory hierarchy that reflects the partitioning structure. This organization can improve the performance of read operations, as queries that filter by the partitioned columns can scan only the relevant directories.
Moreover, partitioning facilitates parallelism because each partition can be processed independently across different nodes in a distributed system like Spark. However, the code snippet provided does not explicitly specify that file compression should be used, so we cannot assume that the output will be compressed without additional context.
References = DataFrame write partitionBy Apache Spark optimization with partitioning
Question 9:
You have a Fabric tenant that contains a Microsoft Power Bl report named Report 1. Report1 includes a Python visual. Data displayed by the visual is grouped automatically and duplicate rows are NOT displayed. You need all rows to appear in the visual. What should you do?
A. Reference the columns in the Python code by index.
B. Modify the Sort Column By property for all columns.
C. Add a unique field to each row.
D. Modify the Summarize By property for all columns.
Correct Answer: C
Explanation: To ensure all rows appear in the Python visual within a Power BI report, option C, adding a unique field to each row, is the correct solution. This will prevent automatic grouping by unique values and allow for all instances of data to be represented in the visual.
References = For more on Power BI Python visuals and how they handle data, please refer to the Power BI documentation.
Question 10:
You have a Fabric tenant that contains a new semantic model in OneLake.
You use a Fabric notebook to read the data into a Spark DataFrame.
You need to evaluate the data to calculate the min, max, mean, and standard deviation values for all the string and numeric columns.
Solution: You use the following PySpark expression:
df.explain()
Does this meet the goal?
A. Yes
B. No
Correct Answer: B
Explanation: The df.explain() method does not meet the goal of evaluating data to calculate statistical functions. It is used to display the physical plan that Spark will execute.
References = The correct usage of the explain() function can be found in the PySpark documentation.
Question 11:
You are analyzing the data in a Fabric notebook.
You have a Spark DataFrame assigned to a variable named df.
You need to use the Chart view in the notebook to explore the data manually.
Which function should you run to make the data available in the Chart view?
A. displayMTML
B. show
C. write
D. display
Correct Answer: D
Explanation: The display function is the correct choice to make the data available in the Chart view within a Fabric notebook. This function is used to visualize Spark DataFrames in various formats including charts and graphs directly within the notebook environment.
References = Further explanation of the display function can be found in the official documentation on Azure Synapse Analytics notebooks.
Question 12:
You have a Fabric tenant that contains a warehouse named Warehouse1. Warehouse1 contains three schemas named schemaA, schemaB. and schemaC.
You need to ensure that a user named User1 can truncate tables in schemaA only.
How should you complete the T-SQL statement? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:

Correct Answer:

GRANT ALTER ON SCHEMA::schemaA TO User1;
The ALTER permission allows a user to modify the schema of an object, and granting ALTER on a schema will allow the user to perform operations like TRUNCATE TABLE on any object within that schema. It is the correct permission to
grant to User1 for truncating tables in schemaA.
References =GRANT Schema Permissions
Permissions That Can Be Granted on a Schema
Question 13:
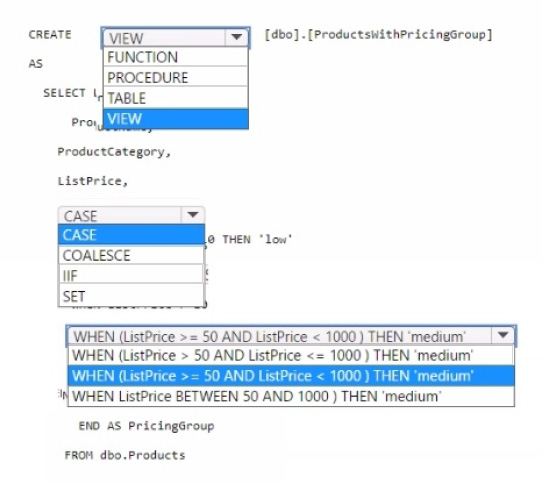
You need to resolve the issue with the pricing group classification.
How should you complete the T-SQL statement? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
Correct Answer:
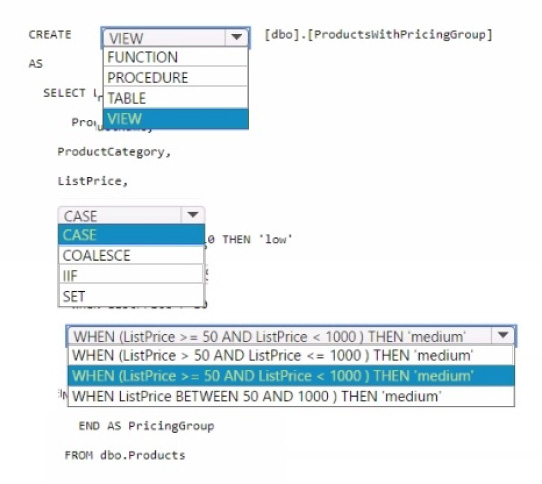
You should use CREATE VIEW to make the pricing group logic available for TSQL queries. The CASE statement should be used to determine the pricing group based on the list price. The T-SQL statement should create a view that classifies products into pricing groups based on the list price.
The CASE statement is the correct conditional logic to assign each product to the appropriate pricing group. This view will standardize the pricing group logic across different databases and semantic models.
Question 14:
You have a Fabric tenant that contains a semantic model. The model uses Direct Lake mode.
You suspect that some DAX queries load unnecessary columns into memory.
You need to identify the frequently used columns that are loaded into memory.
What are two ways to achieve the goal? Each correct answer presents a complete solution.
NOTE: Each correct answer is worth one point.
A. Use the Analyze in Excel feature.
B. Use the Vertipaq Analyzer tool.
C. Query the $system.discovered_STORAGE_TABLE_COLUMN-iN_SEGMeNTS dynamic management view (DMV).
D. Query the discover_hehory6Rant dynamic management view (DMV).
Correct Answer: BC
Explanation: The Vertipaq Analyzer tool (B) and querying the $system.discovered_STORAGE_TABLE_COLUMNS_IN_SEGMENTS dynamic management view (DMV) (C) can help identify which columns are frequently loaded into memory. Both methods provide insights into the storage and retrieval aspects of the semantic model.
References = The Power BI documentation on Vertipaq Analyzer and DMV queries offers detailed guidance on how to use these tools for performance analysis.
Question 15:
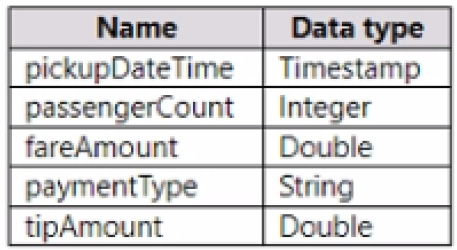
You have a Fabric tenant that contains a lakehouse named Lakehouse1. Lakehouse1 contains a table named Nyctaxi_raw. Nyctaxi_raw contains the following columns.
You create a Fabric notebook and attach it to lakehouse1.
You need to use PySpark code to transform the data. The solution must meet the following requirements:
Correct Answer:
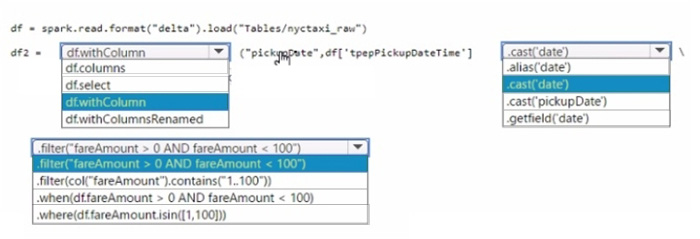
Add the pickupDate column: .withColumn(“pickupDate”,
df[“pickupDateTime”].cast(“date”))
Filter the DataFrame: .filter(“fareAmount > 0 AND fareAmount < 100”)
In PySpark, you can add a new column to a DataFrame using the .withColumn method, where the first argument is the new column name and the second argument is the expression to generate the content of the new column.
Here, we use the .cast(“date”) function to extract only the date part from a timestamp. To filter the DataFrame, you use the .filter method with a condition that selects rows where fareAmount is greater than 0 and less than 100, thus ensuring only positive values less than 100 are included.
Ending
Ready to pass DP-600 exam in no time? Don’t hesitate anymore! Do what it says and you can do it.
This blog covers the entire guide to preparing for the DP-600 exam including study resources, study methods. It provides you with all the information you need to fully prepare for the DP-600 exam. Of course, you must also go to download Pass4itSure DP-600 exam dumps practice questions https://www.pass4itsure.com/dp-600.html (pdf+vce) to practice effectively and improve your exam ability. Let Pass4itSure accompany you to start your journey to become a certified Microsoft Fabric Engineer!