
We are writing this blog post because many people have asked for information about the Microsoft Azure Data Engineer Associate Certification DP-203 exam how to study and the latest exam questions.
Pass4itSure’s new DP-203 exam questions (https://www.pass4itsure.com/dp-203.html) and an unwavering study plan will help you study for the exam correctly and pass it successfully.
DP-203 Exam Details: Data Engineering on Microsoft Azure
The ins and outs of the DP-203 exam: DP-203 has replaced DP-200 and 201 in May 2021. This exam is the next-level version of Implementing Azure Data Solutions [DP-200] and Designing Azure Data Solutions [DP-201]. Azure data engineers are responsible for integrating, transforming, and consolidating data from disparate structured and unstructured data systems into a structure sufficient to build analytics solutions.
Why you need the DP-203 exam: Most IT industries generate large amounts of raw data daily, so a dedicated team is required to integrate, transform, and consolidate data from various structured and unstructured data systems into a structure suitable for building analytics solutions.
Exam Prerequisites: Candidates must be proficient in data processing languages such as SQL, Python, and Scala. It is essential to understand parallel processing and data architecture patterns.
The areas covered and weighted in the DP-203 exam are: 15-20% in designing and implementing data storage, 40-45% in designing and developing data processing, and 30-35% in securing and monitoring data processing and storage
Exam language: English, Chinese (Simplified), Japanese, Korean, German, French, Spanish, Portuguese (Brazil), Arabic (Saudi Arabia), Russian, Chinese (Traditional), Italian, Indonesian (Indonesia)
Cost of Certification: The total registration fee for the DP-203 certification exam is $165.
Last updated: November 2, 2023
Exam duration: 100 minutes in time
Exam method: The exam is invigilated by the invigilator and does not open the book
How to schedule your exam: Schedule through Pearson Vue
Can I renew my certification: Yes
Post-Exam Role: Data Engineer
Is the DP-203 exam difficult, and what is the difficulty: Medium difficulty is that it covers many topics and requires some experience with relevant techniques.
Resources for studying for the DP-203 exam: https://learn.microsoft.com/en-us/credentials/certifications/resources/study-guides/dp-203 https://learn.microsoft.com/en-us/training/paths/get-started-data-engineering/?source=recommendations https://learn.microsoft.com/en-us/credentials/certifications/azure-data-engineer/?source=recommendations&practice-assessment-type=certification https://learn.microsoft.com/en-us/shows/exam-readiness-zone/preparing-for-dp-203-design-and-implement-data-storage-1-of-3?source=recommendations https://learn.microsoft.com/en-us/credentials/ https://learn.microsoft.com/en-us/shows/exam-readiness-zone/preparing-for-dp-203-secure-monitor-and-optimize-data-storage-and-data-processing-3-of-3?source=recommendations https://learn.microsoft.com/en-us/shows/exam-readiness-zone/preparing-for-dp-203-develop-data-processing-2-of-3?source=recommendations https://learn.microsoft.com/en-us/credentials/ https://learn.microsoft.com/en-us/training/courses/dp-203t00
Certifications related to the exam: Azure Database Administrator Associate
When it comes to exams, we have to mention the Azure Database Administrator Associate. What is an Azure Database Administrator Associate?
Azure Database Administrator Associate
The role of Azure Database Administrator or Azure Database Administration Specialist also includes the implementation and management of operational aspects related to cloud-native and hybrid data platform solutions on Microsoft SQL Server and Microsoft Azure Data Services.
In addition, an Azure database administrator or database management specialist must focus on management, performance monitoring, security, optimization of contemporary relational database solutions, and availability.
Specific responsibilities include:
As an Azure Data Engineer, you can help stakeholders understand data through exploration and build and maintain secure and compliant data processing pipelines using different tools and technologies. You use a variety of Azure data services and frameworks to store and build cleaned and enhanced datasets for analysis.
This data store can be designed using different architectural patterns based on business needs. As an Azure Data Engineer, you can also help ensure that your data pipelines and data stores are operated with high performance, efficiency, order, and reliability while meeting a range of business requirements and constraints.
You can help identify and resolve operational and data quality issues. You can also design, implement, monitor, and optimize your data platform to meet the requirements of your data pipeline. You need to understand parallel processing and data architecture patterns. You should be proficient in using the following to create a data processing solution.
Two tips for candidates preparing for the Microsoft Azure DP-203 exam:
- Create a study plan that works for you
- Be unwavering in your study plan
Why? Once you have a study plan that’s right for you, stick to it. Don’t change halfway. A plan that is not persistent enough will never succeed. For example, it is recommended that you start with the new DP-203 exam questions (available on the Pass4itSure website, Pass4itSure’s new DP-203 exam answers cover all the knowledge points of the real exam, and mastering the exam questions is equivalent to mastering the exam. Practice begins and lasts until the arrival of the official exam.
Of course, studying for exams is not limited to this, but also reading official guides, taking online courses, watching video learning, practicing exam questions online, joining discussion groups, and books, taking mock exams, and more. You’ll need to learn a lot to win. Practicing new DP-203 exam questions is just an essential part of the preparation process.
Speaking of exam questions, here are the new DP-203 exam questions for you, the latest (shared by Pass4itSure).
Free online Microsoft Azure Data Engineer Associate Certification DP-203 exam new questions
Question 1:
You have an Azure data factory named ADF1.
You currently publish all pipeline authoring changes directly to ADF1.
You need to implement version control for the changes made to pipeline artifacts. The solution must ensure that you can apply version control to the resources currently defined in the UX Authoring canvas for ADF1.
Which two actions should you perform? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
A. From the UX Authoring canvas, select Set up code repository.
B. Create a Git repository.
C. Create a GitHub action.
D. Create an Azure Data Factory trigger.
E. From the UX Authoring canvas, select Publish.
F. From the UX Authoring canvas, run Publish All.
Correct Answer: AB
To implement version control for changes made to pipeline artifacts in ADF1 while ensuring that version control can be applied to the resources currently defined in the UX Authoring canvas, you should perform the following two actions:
A. From the UX Authoring canvas, select Set up code repository: This will allow you to configure ADF1 to integrate with a version control system such as Git, which will enable you to track changes made to pipeline artifacts over time.
B. Create a Git repository: This will provide the version control system needed to track changes made to pipeline artifacts in ADF1.
Therefore, options A and B are the correct answers.
C, D, E, and F are not relevant to implementing version control for changes made to pipeline artifacts in ADF1.
Question 2:
You have an Azure Data Lake Storage Gen2 account named account1 that contains a container named container1.
You plan to create lifecycle management policy rules for container1.
You need to ensure that you can create rules that will move blobs between access tiers based on when each blob was accessed last.
What should you do first?
A. Configure object replication
B. Create an Azure application
C. Enable access time tracking
D. Enable the hierarchical namespace
Correct Answer: C
Generally available: Access time-based lifecycle management rules for Data Lake Storage Gen2
Some data in Azure Storage is written once and read many times. To effectively manage the lifecycle of such data and optimize your storage costs, it is important to know the last time of access for the data. When access time tracking is
enabled for a storage account, the last access time property on the file is updated when it is read. You can then define lifecycle management policies based on last access time:
Transition objects from hotter to cooler access tiers if the file has not been accessed for a specified duration.
Automatically transition objects from cooler to hotter access tiers when a file is accessed again.
Delete objects if they have not been accessed for an extended duration.
Access time tracking is only available for files in Data Lake Storage Gen2.
Reference:
https://azure.microsoft.com/en-us/updates/access-time-based-lifecycle-management-adls-gen2
Question 3:
You have the following Azure Data Factory pipelines:
1.Ingest Data from System1
2.Ingest Data from System2
3.Populate Dimensions
4.Populate Facts
Ingest Data from System1 and Ingest Data from System2 have no dependencies. Populate Dimensions must execute after Ingest Data from System1 and Ingest Data from System2. Populate Facts must execute after the Populate Dimensions pipeline. All the pipelines must be executed every eight hours.
What should you do to schedule the pipelines for execution?
A. Add an event trigger to all four pipelines.
B. Add a schedule trigger to all four pipelines.
C. Create a patient pipeline that contains the four pipelines and use a schedule trigger.
D. Create a patient pipeline that contains the four pipelines and use an event trigger.
Correct Answer: C
Schedule trigger: A trigger that invokes a pipeline on a wall-clock schedule.
Reference: https://docs.microsoft.com/en-us/azure/data-factory/concepts-pipeline-execution-triggers
Question 4:
You are designing an Azure Stream Analytics solution that will analyze Twitter data.
You need to count the tweets in each 10-second window. The solution must ensure that each tweet is counted only once.
Solution: You use a hopping window that uses a hop size of 5 seconds and a window size 10 seconds.
Does this meet the goal?
A. Yes
B. No
Correct Answer: B
Instead, use a tumbling window. Tumbling windows are a series of fixed-sized, non-overlapping, and contiguous time intervals.
Reference: https://docs.microsoft.com/en-us/stream-analytics-query/tumbling-window-azure-stream-analytics
Question 5:
You need to integrate the on-premises data sources and Azure Synapse Analytics. The solution must meet the data integration requirements. Which type of integration runtime should you use?
A. Azure-SSIS integration runtime
B. self-hosted integration runtime
C. Azure integration runtime
Correct Answer: C
Question 6:
You are designing an Azure Databricks interactive cluster. The cluster will be used infrequently and will be configured for auto-termination. You need to use that the cluster configuration is retained indefinitely after the cluster is terminated. The solution must minimize costs. What should you do?
A. Pin the cluster.
B. Create an Azure runbook that starts the cluster every 90 days.
C. Terminate the cluster manually when processing completes.
D. Clone the cluster after it is terminated.
Correct Answer: A
Azure Databricks retains cluster configuration information for up to 70 all-purpose clusters terminated in the last 30 days and up to 30 job clusters recently terminated by the job scheduler. To keep an all-purpose cluster configuration even after it has been terminated for more than 30 days, an administrator can pin a cluster to the cluster list.
Reference: https://docs.microsoft.com/en-us/azure/databricks/clusters/
Question 7:
You use Azure Stream Analytics to receive Twitter data from Azure Event Hubs and to output the data to an Azure Blob storage account.
You need to output the count of tweets from the last five minutes every minute.
Which windowing function should you use?
A. Sliding
B. Session
C. Tumbling
D. Hopping
Correct Answer: D
Hopping window functions hop forward in time by a fixed period. It may be easy to think of them as Tumbling windows that can overlap and be emitted more often than the window size. Events can belong to more than one Hopping window result set. To make a Hopping window the same as a Tumbling window, specify the hop size to be the same as the window size.
Reference: https://docs.microsoft.com/en-us/azure/stream-analytics/stream-analytics-window-functions
Question 8:
HOTSPOT
You plan to develop a dataset named Purchases by using Azure Databricks. Purchases will contain the following columns:
1.ProductID
2.ItemPrice
3.LineTotal
4.Quantity
5.StoreID
6.Minute
7.Month
8.Hour
9.Year 10.Day
You need to store the data to support hourly incremental load pipelines that will vary for each Store ID. The solution must minimize storage costs.
How should you complete the code? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:

Correct Answer:
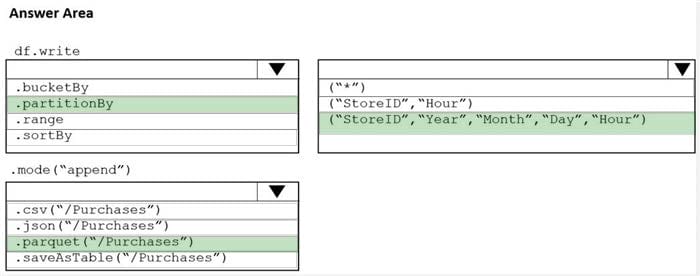
Box 1: partition
We should overwrite at the partition level.
Example:
df. write.partition(“y”, “m”, “d”)
.mode(SaveMode.Append)
.parquet(“/data/hive/warehouse/db_name.db/” + tableName)
Box 2: (“StoreID”, “Year”, “Month”, “Day”, “Hour”, “StoreID”)
Box 3: parquet(“/Purchases”)
Reference:
Question 9:
HOTSPOT
You store files in an Azure Data Lake Storage Gen2 container. The container has the storage policy shown in the following exhibit.
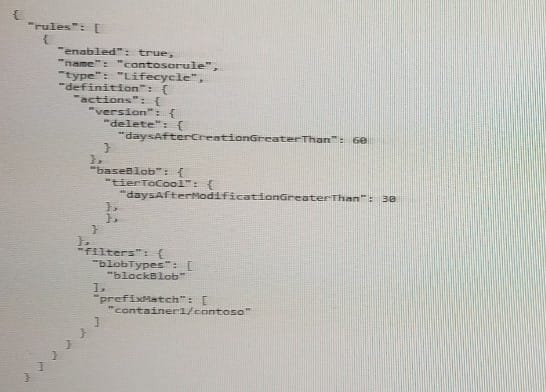
Use the drop-down menus to select the answer choice that completes each statement based on the information presented in the graphic. NOTE: Each correct selection Is worth one point.
Hot Area:

Correct Answer:

Question 10:
You plan to create an Azure Databricks workspace that has a tiered structure. The workspace will contain the following three workloads:
1. A workload for data engineers who will use Python and SQL.
2. A workload for jobs that will run notebooks that use Python, Scala, and SOL.
3. A workload that data scientists will use to perform ad hoc analysis in Scala and R.
The enterprise architecture team at your company identifies the following standards for Databricks environments:
1. The data engineers must share a cluster.
2. The job cluster will be managed by using a request process whereby data scientists and data engineers provide packaged notebooks for deployment to the cluster.
3. All the data scientists must be assigned their cluster that terminates automatically after 120 minutes of inactivity. Currently, there are three data scientists.
You need to create the Databricks clusters for the workloads.
Solution: You create a Standard cluster for each data scientist, a high-concurrency cluster for the data engineers, and a High Concurrency cluster for the jobs.
Does this meet the goal?
A. Yes
B. No
Correct Answer: A
We need a High Concurrency cluster for the data engineers and the jobs.
Note:
Standard clusters are recommended for a single user. Standard can run workloads developed in any language: Python, R, Scala, and SQL.
A high-concurrency cluster is a managed cloud resource. The key benefits of high concurrency clusters are that they provide Apache Spark-native fine-grained sharing for maximum resource utilization and minimum query latencies.
Reference:
https://docs.azuredatabricks.net/clusters/configure.html
Question 11:
DRAG DROP
You are designing an Azure Data Lake Storage Gen2 structure for telemetry data from 25 million devices distributed across seven key geographical regions. Each minute, the devices will send a JSON payload of metrics to Azure Event Hubs.
You need to recommend a folder structure for the data. The solution must meet the following requirements:
1. Data engineers from each region must be able to build their pipelines for the data of their respective regions only.
2. The data must be processed at least once every 15 minutes for inclusion in Azure Synapse Analytics serverless SQL pools.
How should you recommend completing the structure? To answer, drag the appropriate values to the correct targets. Each value may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.
Select and Place:

Correct Answer:

Box 1: {regionID}/raw
Data engineers from each region must be able to build their pipelines for the data of their respective regions only.
Box 2: {YYYY}/{MM}/{DD}/{HH}
Date Format [optional]: if the date token is used in the prefix path, you can select the date format in which your files are organized. Example: YYYY/MM/DD
Time Format [optional]: if the time token is used in the prefix path, specify the time format in which your files are organized. Currently, the only supported value is HH.
Box 3: {deviceID}
Reference: https://github.com/paolosalvatori/StreamAnalyticsAzureDataLakeStore/blob/master/README.md
Question 12:
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while
others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You are designing an Azure Stream Analytics solution that will analyze Twitter data.
You need to count the tweets in each 10-second window. The solution must ensure that each tweet is counted only once.
Solution: You use a session window that uses a timeout size of 10 seconds.
Does this meet the goal?
A. Yes
B. No
Correct Answer: B
Instead, use a tumbling window. Tumbling windows are a series of fixed-sized, non-overlapping, and contiguous time intervals.
Reference: https://docs.microsoft.com/en-us/stream-analytics-query/tumbling-window-azure-stream-analytics
Question 13:
HOTSPOT
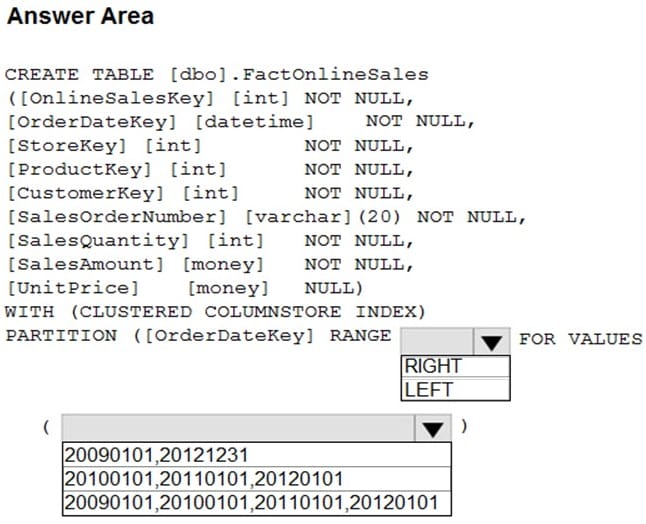
You have an enterprise data warehouse in Azure Synapse Analytics that contains a table named FactOnlineSales. The table contains data from the start of 2009 to the end of 2012.
You need to improve the performance of queries against FactOnlineSales by using table partitions. The solution must meet the following requirements:
1. Create four partitions based on the order date.
2. Ensure that each partition contains all the orders placed during a given calendar year.
How should you complete the T-SQL command? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
Correct Answer:
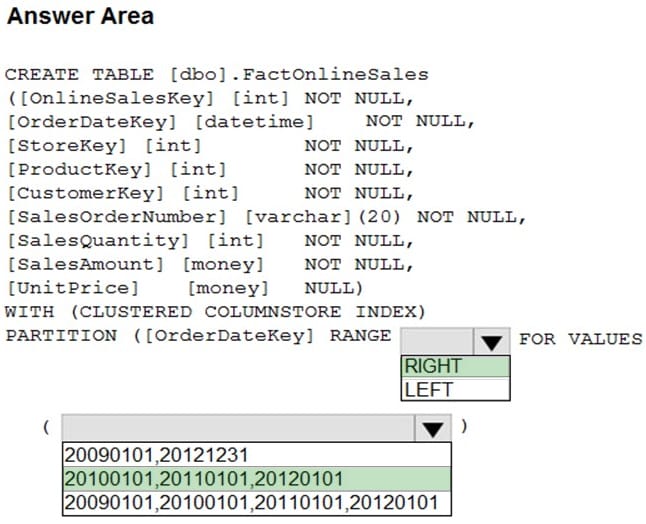
Range Left or Right, both create similar partition but there is a difference in comparison
For example: in this scenario, when you use LEFT and 20100101,20110101,20120101 Partition will be, datecol<=20100101, datecol>20100101 and datecol<=20110101, datecol>20110101 and datecol<=20120101, datecol>20120101 But if you use range RIGHT and 20100101,20110101,20120101
The partition will be, datecol<20100101, datecol>=20100101 and datecol<20110101, datecol>=20110101 and datecol<20120101, datecol>=20120101 In this example, Range RIGHT will be suitable for calendar comparison Jan 1st to Dec 31st Reference:
Question 14:
You create an Azure Databricks cluster and specify an additional library to install.
When you attempt to load the library to a notebook, the library in not found.
You need to identify the cause of the issue.
What should you review?
A. notebook logs
B. cluster event logs
C. global init scripts logs
D. workspace logs
Correct Answer: C
Cluster-scoped Init Scripts: Init scripts are shell scripts that run during the startup of each cluster node before the Spark driver or worker JVM starts. Databricks customers use init scripts for various purposes such as installing custom libraries, launching background processes, or applying enterprise security policies.
Logs for Cluster-scoped init scripts are now more consistent with Cluster Log Delivery and can be found in the same root folder as driver and executor logs for the cluster.
Reference: https://databricks.com/blog/2018/08/30/introducing-cluster-scoped-init-scripts.html
Question 15:
You have an Azure Data Factory pipeline that is triggered hourly.
The pipeline has had 100% success for the past seven days.
The pipeline execution fails, and two retries that occur 15 minutes apart also fail. The third failure returns the following error.
ErrorCode=UserErrorFileNotFound,\’Type=Microsoft.DataTransfer.Common.Shared.HybridDeliveryException, Message=ADLS Gen2 operation failed for: Operation returned an invalid statuscode \’ NotFound\’. Account: \’contosoproduksouth\’. Filesystem: wwi. Path: \’BIKES/CARBON/year=2021/month=01/day=10/hour=06\’. ErrorCode: \’PathNotFound\’. Message: \’The specified path does not exist.\’. RequestId: \’6d269b78-901f-001b-4924-e7a7bc000000\’. TimeStamp: \’Sun, 10 Jan 2021 07:45:05
What is a possible cause of the error?
A. From 06.00 to 07:00 on January 10.2021 there was no data in w1/bikes/CARBON.
B. The parameter used to generate year.2021/month=0/day=10/hour=06 was incorrect
C. From 06:00 to 07:00 on January 10, 2021, the file format of data wi/BiKES/CARBON was incorrect
D. The pipeline was triggered too early.
Correct Answer: B
How can I tell if I’m ready for the DP-203 exam?
If you have consistently performed well in practicing the DP-203 exam questions and have done it 100% correctly, then you are ready to give it a try.
Data engineering positions are in high demand
In today’s fast-paced society, with the rapid rise of artificial intelligence, there is a lot of data processing work, and according to the data released by Burning Glass’s Nova platform, the company is in a very short supply of “data engineers” and other positions that need to work with massive data sets. Therefore, it is very useful for you to pass the DP-203 exam, even if you need to put in a lot of work to get through the difficult exam, it is worth it, and getting the certification means getting a good position.
Write at the end:
How do I study to prepare for the Microsoft Azure Data Engineer Associate certification DP-203 exam?
To put it simply, you need to understand the details of the exam, be determined to execute your study plan and be good at using Pass4itSure’s new DP-203 exam questions (https://www.pass4itsure.com/dp-203.html) to practice effectively.
Good luck!
Hope you find these suggestions helpful and good luck! If you have any other questions, feel free to ask me on Facebook.